the story of HOD - ahead of its time, obsolete at launch
We've been using AWS as long as bizo has been around, since early 2008. Hadoop has always been a big part of that. When we first started, we were mostly using a shared hadoop cluster. This was kind of a pain for job scheduling, but also was mostly wasteful during off-peak hours... Thus, HOD was born.
From its documentation, "The goal of HOD is to provide an on demand, scalable, sandboxed infrastructure to run Hadoop jobs." Sound familiar? HOD was developed late September and October of 2008, and launched for internal use December 12th, 2008. Amazon announced EMR April of 2009. It's amazing how similar they ended up being... especially since we had no knowledge of EMR at the time. Even though HOD had a few nice features missing from EMR, the writing was on the wall. For new tasks, we wrote them for EMR. We slowly migrated old reports to EMR when they needed changes, or we had the time.
Architecture
HOD borrowed quite liberally from the design of Alexa's GrepTheWeb.
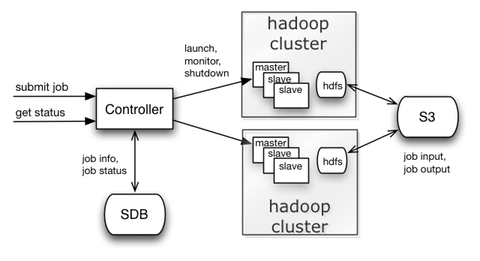
Users submitted job requests to a controller which managed starting exclusive hadoop clusters (master, slaves, hdfs), retrieving job input from S3 to HDFS, executing the job (hadoop map/reduce), monitoring the job, storing job results, and shutting down the cluster on completion. Job information and status was stored in SimpleDB, S3 was used for job inputs and outputs, and SQS was used to manage the job workflow.
Job Definition
Jobs were defined as thrift structures:
struct JobRequest {
1: JobConf job = {},
2: i32 requested_nodes = 4, // requested number of hadoop slaves
3: string node_type = "m1.large", // machine size
4: i32 requested_priority, // job priority
5: string hadoop_dist, // hadoop version e.g. "0.18.3"
6: set depends_on = [], // ids of job dependencies
7: list on_success = [], // success notification
8: list on_failure = [], // failure notification
9: set flags = [] // everyone loves flags
}
struct JobConf {
1: string job_name,
2: string job_jar, // s3 jar path
3: string mapper_class,
4: string combiner_class,
5: string reducer_class,
6: set job_input, // s3 input paths
7: string job_output, // s3 output path (optional)
8: string input_format_class,
9: string output_format_class,
10: string input_key_class,
11: string input_value_class,
12: string output_key_class,
13: string output_value_class,
// list of files for hadoop distributed cache
14: set user_data = [],
15: map other_config = {}, // passed directly JobConf.set(k, v)
}
You'll notice that dependencies could be specified. HOD could hook up the output of 1 or more jobs into the input of a job and wouldn't run the job until all of its dependencies have successfully completed.
User Interaction
We had a user program, similar to emr-client that helped construct and job jobs, e.g.:
JOB="\
-m com.bizo.blah.SplitUDCMap \
-r com.bizo.blah.UDCReduce \
-jar com-bizo-release:blah/blah/blah.jar
-jobName blah \
-i com-bizo-data:blah/blah/blah/${MONTH} \
-outputKeyClass org.apache.hadoop.io.Text \
-outputValueClass org.apache.hadoop.io.Text \
-nodes 10 \
-nodeType c1.medium \
-dist 0.18.3 \
-emailSuccess larry@bizo.com \
-emailFailure larry@bizo.com \
"
$HOD_HOME/bin/hod_submit $JOB $@
There was also some support for querying jobs:

As well as support for viewing job output, logs, counters, etc.
Nice features
We've been very happy users of Amazon's EMR since it launched in 2009. There's nothing better than systems you don't need to support/maintain yourself! And they've been really busy making EMR more easy to use and adding great features. Still, there are a few things I miss from HOD.
Workflow support
As mentioned, HOD had support for constructing job workflows. You could wire up dependencies amount multiple jobs. E.g. here's an example workflow
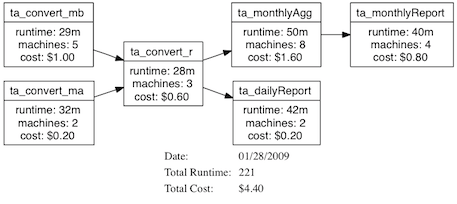
It would be nice to see something like this in EMR. For really simple workflows, you can sometime squeeze them into a single EMR job as multiple steps, but that doesn't always make sense and isn't always convenient.
Notification support
HOD supported notifications directly. Initially just email notifications, but there was a plugin structure in place with an eye towards supporting HTTP endpoint, and SQS notifications.Yes, this is possible by adding a custom EMR job step at the end that checks the status of itself and sends an email/failure notification... But, c'mon, why not just build in easy SNS support? Please?
Counter support
Building on that, HOD had direct support/understanding for hadoop counters. When processing large volumes of data, they become really critical in tracking the health of your reports over time. This is something I really miss. Although, it's less obvious how to fold this in with Hive jobs, which is how most of our reports are written these days.
Arbitrary Hadoop versions
HOD operated with straight hadoop, so it was possible to have it install an arbitrary version/package just by pointing it to the right distribution in S3.Since Amazon isn't directly using a distribution from the hadoop/hive teams, you need to wait for them to apply their patches/changes and can only run with versions they directly support. This has mostly been a problem with Hive, which moves pretty quickly.It would be really great if they could get to a point where their changes have been folded back into the main distribution.Of course, this is probably something you can do yourself, again with a custom job step to install your own version of Hive… Still, they have some nice improvements, and again, it would be nice if it were just a simple option to the job.
The Past / The Future
Of course, HOD wasn't without its problems :). It's become a bear to manage, especially since we pretty much stopped development / maintenance (aside from rebooting it) back in 2009. It was definitely with a sigh of relief that I pulled the plug.
Still, HOD was a really fun project! It was an early project for me at Bizo, and it was really amazing how easy it was to write a program that starts up machines! and gets other programs installed and running! Part of me wonders if there isn't a place for an open source EMR-like infrastructure somewhere? Maybe for private clouds? Maybe for people who want/need more control? Or for cheapskates? :)
Or maybe HOD v2 is just some wrappers around EMR that provides some of the things I miss : workflow support, notifications, easier job configuration...Something to think about for that next hack day :).